Usage Stories
This page has existed for a while, offering some more esoteric examples of SQL-Hero's power. We're leaving those stories here (further down), because it's important to understand that the product is extremely deep. But we do want to provide some more day-to-day practical examples as well, of how SQL-Hero is being used to help developers - not just SQL developers - be more effective. In the examples that follow, "company" refers to users of SQL-Hero who have benefited from its features.
Also note that we have more to say about the newest features of the product, especially in the areas covered by Performance daggor™ and Extended Event capture. These are quite new, so check back in a bit and we'll have more to say as it relates to real live examples.
- Understanding the Impact of a Server Change
-
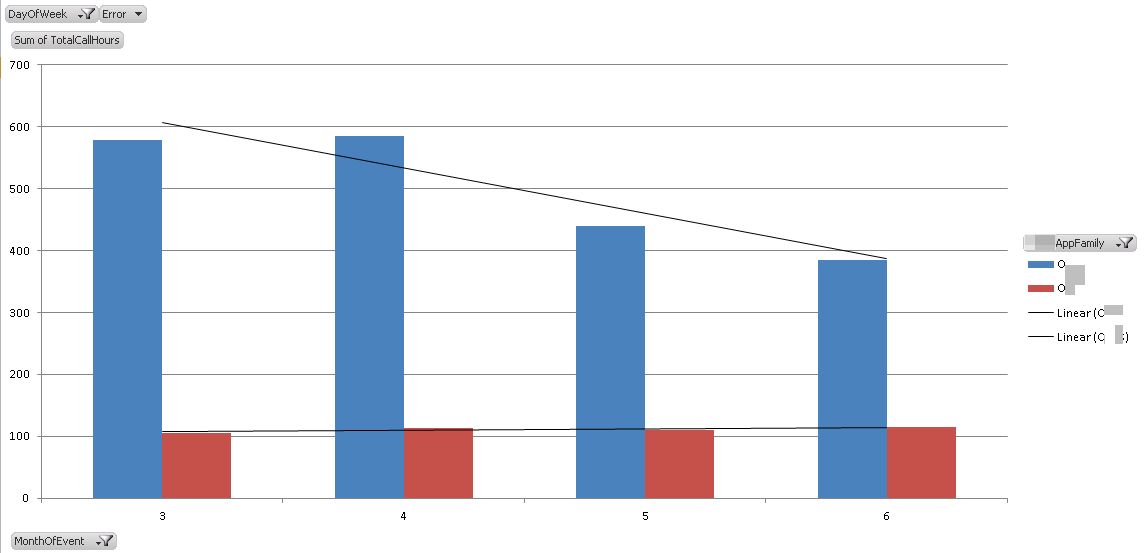
With 32Gb of RAM installed in 2 different production SQL boxes, the customer was getting "meh" performance out of various applications that used these boxes. The boxes were old but could be upgraded to 64Gb of RAM. The infrastructure manager asked if there was a way to use the data that SQL-Hero had been collecting for the last several years to see what the effect of doubling the RAM would be. This was at a time when they were using version 0.9.8 of the product, and although the great data warehouse features of 0.9.9 were not yet available, the raw data was available and actually helped drive some of the proof-of-concept work for 0.9.9. Ultimately we gave them a report that shows time on the x-axis, cumulative duration of all "long" procedure calls on the y-axis. This is implemented in Excel as a Pivot Table, so it's easy to add other slicers, adjust filters, and so on. The source data is based on Power Pivot, which was a precursor to doing similar things using the SSAS Tabular Model starting in release 0.9.9. Even before adding a trend-line, it was very evident that the doubling of RAM had made a distinct improvement for one of the two application families. Knowing this fact was useful in its own right and overall helped justify the move to both managers and users.
- Connection Management and Change Tracking
-
With approximately 100 different databases used throughout the organization, it would be a pain to have to remember all the machine names, database names and so on. Instead, we've set it up so database aliases used by SQL-Hero typically have the application name followed by the environment. For example "HR-Development" or "Payroll-QA". The company's choice has been to use shared databases for development, as opposed to individual developer sandbox databases, or creating a central source of truth in the file system and placing that under source control. There are clearly advantages and disadvantages. Developers must be rigorous in their tracking of changes, and these are recorded in a bug tracking system. SQL-Hero does offer some additional tools related to build management, but these have not been leveraged to the maximum extent possible yet. Developers do appreciate the fact that they can develop against multiple SQL objects in concert and test these in a development database where the data architects can present schema changes to the whole team, plus develop a common understanding of what the data will look like. There has been more than one occasion where the change history for objects has been very useful to help understand who did what and when. If we imagine that a central source of truth was the file system, we might be able to tell when a change was officially committed, but not necessarily all versions of it that were there as a developer did their work in debugging and testing. Sometimes those intermediate changes are important to figure out intent. It's very easy within SQL-Hero to compare an object's text between different databases, or from the current version to a past version. Many issues have been settled quickly because a DBA could present a complete history for an object in production where one would think a source control system should give a perfect picture in itself, but sometimes is incomplete, based on real-life experience.
- Scheduled Trace Reports
-
The company's DBA had on his own initiative at some point set up an on-going SQL Profiler session for two key production databases that would capture all calls taking more than 5 seconds or returning a non-zero error code. He had this populate a table in a work database. SQL-Hero was set up to monitor this table and aggregate trace information into the SQL-Hero repository. The DBA liked having his original table to look at as well, so the option was used to not remove the trace records from the source table. It's important to note that when SQL-Hero aggregates special events such as the "Deadlock Report" and "Blocking Report", extra information that's present in those reports is "shredded" by SQL-Hero to capture a lot of detail that can be important and in fact may otherwise be transient (if for example the SQL Server instance were recycled, the SQL handles would no longer give you the desired detail). With trace data now in both places, some trace reports were scheduled to be delivered by email. Some were set to be hourly including the "Failure Detail" report, and it was targeted by application to a developer distribution list who were familiar with each application. Some reports were scheduled to be delivered daily including the "Failure Summary" report, the "Errors and Slow Calls" report, and the "Average Duration" report. The latter ones were also to be distributed to the Application Development Manager and Operations Manager. These individuals were very interested in the results and it helped guide some focused efforts at reducing some lingering production problems. It was not a magic bullet - it still demanded some rigor and process, but with the reports running over the long-term, one could see improvements - or the occasional misstep. It helped facilitate more discussion, and some additional reports were scheduled to be delivered weekly and monthly to show long term trends by database and application.
- Compliance
-
The company has certainly tried to enforce a build process - but as sometimes happens in the real world, exceptions occur. This has become increasingly rare, but it is still the case that if you were to compare QA and production for a given large application at any given time, you are likely to find a few differences that are not strictly changes pending promotion to production. Now, a lot of competitor products would try to mitigate that by saying "run a compare" between the databases regularly - and you can actually do this with SQL-Hero as well (that is, schedule a compare that gets delivered as a report via email). However, SQL-Hero "knows" more information and can go one step better than a simple compare. It can tell that an object is truly newer in production than in QA and that its text is materially different. This qualifies it as being out of compliance. Furthermore, we have the name of the developer who changed it more recently in production. All of this comes together in the "region differences" tool of SQL-Hero which can send emails based on compliance problems, or provide the information right within SQL-Hero itself. We have run the region difference checks both manually and automatically and the main issues are between development and QA - but most developers say, "oopse, sorry, my bad" and correct the problems quickly - but things would have continued to get more and more out-of-sync if this process were not in place. This reporting isn't meant to be combative: most say "thanks!" when presented with the information.
- Code Generation
-
The company has developed its own application framework that resembles other frameworks such as Entity Framework, nHibernate, CSLA, etc. An important part of this is to generate business objects that relate to the underlying database. The flexibility of the framework has grown with time and now supports not just a table-to-entity mapping. Different kinds of code can get generated including: enumerations from table contents, business objects which use said enumerations, constants that relate to the underlying schema (such that now developers rarely need to hardcode a column name, for example, meaning database changes result in compile time errors instead of run-time errors - very desirable!), stored procedure wrappers which can either extend existing entities or create entirely new ones, and so on. All of this supports some powerful capabilities which allow for rich applications to be developed very quickly - as has been proven in recent work which has fared very well in the face of change. It's no surprise that the CodeX Framework shares some traits with all of the frameworks listed above - while a key goal is to remain fairly simple to work with and understand. The Visual Studio integration that SQL-Hero provides with the .sqlheroproj project type is being used frequently during development to mass update specific code-generated files, although developers have other ways to interact with the code that SQL-Hero generates, meaning everyone on the team can be effective.
- Tracing and the SQL Editor
-
Some of the company's developers are familiar with SQL Profiler and like to use it - which is fine. Other developers like to use SQL-Hero's tracing tool which offers similar capabilities, but with fewer keystrokes to get things running, better grid features, color coding, and so on. The more SQL-Hero savvy have used its trace analysis tools to convey important information to managers about average execution times, using the grid export options to directly paste tables into emails. Another way the tool is helpful is when a business analyst complains about a search not returning data they expected, the developer can ask them to run the search while they have a trace running. From the trace grid, double-clicking the captured procedure call scripts it out to an editor window, ready for re-execution with all the needed parameters. From there, the developer can use the "replace variables" capability of the SQL Editor to build a SQL statement that represents the search's query, and filters in the WHERE clause can be removed one-by-one until data starts coming back - and very quickly issues in the data (or in the BA's understanding!) can be revealed. Not all developers use the SQL-Hero editor, mind you - but that's not a problem: SQL-Hero does not demand by necessity that you always use it... in fact, the change tracking feature works even if a developer uses a competitor's editor. What you will find is that there's a synergy between the different tools, as is illustrated by the trace tool and the SQL editor. Also note that the new advanced trace reporting capabilities are going to prove very helpful the next time a problem is reported in some of the more complex processes that go on concurrently - we can leverage the trace data aggregated in the repository, or run some ad hoc traces as well and then view the results graphically to understand failure points and performance issues more easily.
- SHCommand Command Line Tool (Builds)
-
As part of the process of releasing application builds for user testing, one project team promotes their database changes in full from a development database to a QA database. (Another application that shares the same database uses a different QA database, but that's not overly material for this example.) Rather than involve the company DBA for every build, the team uses a .shcommand file that specifies tasks for a) moving schema changes in the history database associated with the project, b) moving schema changes in the main database associated with the project, c) moving data in certain key code tables, d) emailing the team upon completion with the scripts that were applied plus any errors that were encountered. Furthermore, since the database holds thousands of objects, only schema changes applied in the last three weeks need be considered (builds are done at minimum weekly). This process has sped up the overall time from starting a build to having it ready for users to a matter of less than 10 minutes, typically, as command scripts do most of the work. The DBA's are called on to do less work now - and they're as happy as the developers who have fewer people to wait on.
- Object Change Notifications and Automated Unit Testing
-
A team of developers started work on a new system recently. The team included a data architect who was responsible for adding to and changing an existing database schema to support the application. The requirements were not fully defined up front and as such, changes would come "trickling in" as development proceeded. To make it easier on the team, the architect set up SQL-Hero object change notification so that within 60 minutes of his making schema changes on tables, team members would get an email listing all the tables he had altered or created. Although there was often communication about this ahead of time among the whole team (to make sure everyone understood what was going on!), this notification system was helpful because a) the timing of the changes was sometimes unclear due to other things going on - the automated email helped confirm the actual time these were applied and b) served as a reminder of what was actually being changed. Going hand-in-hand with this, the architect made sure that scheduled unit testing of SQL objects was set to run frequently - twice an hour in this case. As such if he did have to make schema changes that broke objects, developers who worked on those objects would get notified within a short period of time. The entire process is very unobtrusive to all developers involved, required only a few minutes of set up by the architect, and now provides extra information that has proven useful on many occasions.
Given the massive depth and breadth of features that SQL-Hero covers, we can't provide just two or three - or a dozen - different usage scenarios. However from a practial standpoint, we've selected a number of real cases that SQL-Hero has been tossed into and we've documented them here.
- Timeouts, Tracing, Grid Tools and Schema Change History
-
The following actual scenario played itself out at a client recently, and stands as an example of how SQL-Hero helped answer a question that might otherwise have taken more research and digging.
Paul was debugging a problem with an application, noticing that a SQL error was being thrown when a shipment was being saved. He asked Bob what might be going on here, since on the surface it seemed like a simple update was being done. He knew that a trigger might be involved but wasn't sure the best way to track down the exact statement in question.
Within seconds Bob had SQL-Hero's tracing tool open and ready to go. (He was already working within Visual Studio, and so this was only a couple of clicks of effort.) From there, he simply picked the desired database, selected "Detailed - Timeouts and Deadlocks", and clicked on "Start".
Paul ran through the process to make the failure happen again. Bob paused the trace, filtered the trace grid, and chose to limit the output based on the ApplicationName column (there was other data cluttering the view such as from replication). Scrolling to near the bottom, the offending statement became obvious in seconds. Bob could even double-click on the statement in the trace grid and make its text appear in a SQL editor window, ready to run.
Paul immediately realized the issue was in how the offending statement was assuming that only one record might be updated in the trigger, yet he had found a case now where multiple rows were being updated. The next question that neither of them could answer was "what's the real intent of this statement / logic?" Should the statement be phrased as an "EXISTS", or "MAX" or some other means to eliminate the multiple rows that were causing the subquery to blow up?
Bob noted to Paul that he could simply right-click on the trigger and pick 'Show History'. This immediately showed who modified it and when. Sure enough, one of their colleagues had changed it recently. To be sure of this, Paul filtered the history grid, and applied a custom 'LIKE' column filter against the 'Text' column, looking for some text specific to the subquery. Sure enough, their suspicions were confirmed.
From this quick and easy research, they were able to track down their colleague and get him to provide a solution, knowing the intent of the logic. This all played itself out in about 1-2 minutes.
- Diagnosing Data Issues: Tracing, Object Navigation and Replace Variables
-
This scenario has played itself out numerous times for our developer, Bob, when he's been forced to solve problems that involve diagnosing why data appears the way it does - most often when users are expecting data to be returned when none actually is.
In one particular case, Bob was told that a function within an application was not 'finding a match' when the user expected it to. Bob's response was to ask the user to invoke their matching operation while he ran a database trace. (A trace, incidentally, he did using SQL-Hero, right within Visual Studio without missing a beat on his development tasks.) In doing so, he captured the stored procedure call that was returning no records. He double-clicked on the trace record with the call and it was scripted to a SQL editor window for the correct database.
Next, he highlighted the procedure name in the SQL editor window and clicked "Locate Object" (F2 also works), opening the procedure text. He noticed the procedure was quite large with a number of steps - where to begin?
He fairly quickly found a SELECT statement that seemed somewhat key to the procedure. If he were using SQL Server Management Studio, he'd likely copy out the text of the SELECT to another window and proceed to change all the local variables and parameters to literal values - those values that were passed to the procedure or otherwise determined within the procedure. Since he was using the SQL-Hero editor, however, he simply highlighted the SELECT statement and clicked on 'Replace Variables in Selection' (F4 also works). This brought up a convenient grid in which he entered the literal values. When he didn't remember one, he'd cancel out of the window, switch back to the procedure call text for example, and re-invoke the replace parameters grid again later - previous values being 'remembered' across invocations.
After providing all the literal values, the resulting SELECT statement was placed in a new SQL editor window with all the substitutions made. From here, Bob trimmed out parts of the WHERE clause until data starting being returned. In doing so, it became clearer as to why no results were being returned (it turned out to be a business rule table configuration issue), Bob advised the user, and it was all done in less than two minutes.
- Automated testing saves another developer future pain
-
Bob was busy developing some stored procedures that were fairly complex. He valued the SQL auto-completion built into SQL-Hero and adopted it as his favored SQL editor. His development was going well until he tried committing a procedure change and got a message back from SQL-Hero saying, "Invalid object name 'Cient'." By scanning the message he realized that he'd created a typo in his code: a table name that he'd accidentally hit Delete on, changing it from "Client" to "Cient". What does SQL Management Studio say when committing this procedure? "Command(s) completed successfully." Yes, you'd hope Bob would test this procedure before it got too far out there, but with SQL-Hero, he knows right away there's a problem. A more insidious problem that scheduled unit testing would catch is if say in this example, Bob's procedure "breaks" due to another developer renaming a column that he uses in one of his queries, after Bob has finished working on it. A notification can even be set up to deal with that situation by informing both Bob and the modifier with an e-mail message.
- Fixing a timeout error even before it was reported by the user
-
Bob received an e-mail from SQL-Hero's notification engine saying that a search stored procedure had timed out in production. The message included the parameters that were used and the duration before it timed out. Concerned that this procedure was used often and he had now seen this message for a fourth time that day, Bob copied the actual SQL that had failed into a SQL editor window and started examining execution plans. The color coding within SQL-Hero's portrayal of the plan quickly highlighted some problem spots in red, and Bob used his knowledge to create a new index that addressed the problem. He was confident this would solve the problem, got permission to deploy it, and never saw the issue show up again.
How did SQL-Hero know to send along this error to Bob? The company DBA had set up an on-going trace with a filter that would write out SQL Profiler-collected events that exceed 10 seconds or have an Error code to a table. Bob set up SQL-Hero to aggregate this trace table data into the SQL-Hero repository, and he also set up a Notification with an e-mail delivery option based on "stored trace" items that exceed duration thresholds or had encountered an error.
- Resurrecting deleted data using SQL-Hero templates
-
Ted had been configuring some meta-data and in the process, accidentally deleted a few critical records in a table. The actual data was not something he could replace himself: some of the values were unknown to him and the user who had initially set it up was no longer with the company. He knew he could go back to the DBA and ask for an old backup: but the database was very large and getting these records restored could take quite some time. In the meantime, some EDI files had to go out in less than 20 minutes that relied on this data. Ted also knew that this table had audit tracking set up on it, recording all inserts, updates and deletes. But how he could actually "resurrect" these deleted records was a bit beyond his SQL knowledge, so he approached Bob.
Bob and Ted talked for a couple of minutes to identify the records. Bob wrote a query against the history table to bring back the records into a result grid. After looking at the results in more detail, Bob and Ted agreed to only import a subset of the rows, so Bob highlighted the desired rows in the grid. He then invoked the SQL-Hero template called "INSERT With VALUES (Results)" against the result grid itself. He was prompted for the columns to include in the generated INSERT's, plus the target table name. This resulted in a few INSERT statements that were placed in the current SQL editor window. Bob simply ran these INSERT's, and the data was returned to its proper state in less than 5 minutes from when the problem first developed.
- Recovering lost work using History Search
-
Paul had been working on a number of changes in a series of triggers in development and was starting to believe he was getting close to a working solution. However after talking to Bob about some of the financial implications of what he'd coded, he realized that a version of his work from approximately two hours ago was more correct than what he had finally arrived at. Unfortunately for him, this older version bore only slight resemblance to the current code. Paul was obviously not going to be copying and pasting each version of the code to a side location as he did his work - but he did commit his changes as an "ALTER TRIGGER" as he went, so he could do some testing. Luckily for Paul, by committing these changes, SQL-Hero had a record of each and every version of his work.
Paul selected his trigger in the SQL-Hero editor, right-clicked on it to get a context menu and picked the "Show History" option. He was directed to the History Search tool, and immediately saw a number of versions of his work throughout the day. Using the date and time that each version was applied (and doing a bit of comparing of versions using the text comparison options available within the History Search tool), he tracked down the desired version's text. He decided to bring back the older version and start making changes from that. It was as simple as him double-clicking on the search result row corresponding to the version he wanted: the text for that version was placed into a SQL Editor window, ready for execution and thereby overwrite of the current version.
- Finding all 3-part names in all SQL objects
-
Paul and Bob decided it was time to move a large application away from its tendency to use 3-part object names in many of its database objects. The alternative was to create 2-part name synonyms for each of these, and the synonyms themselves were created fairly easily using a SQL-Hero template. The bigger piece of work was to track down all cases where 3-part names were being used. Bob pointed out that SQL-Hero supports object content searching using regular expressions. Paul took this as a chance to bone up on regular expressions and came up with the following:
(?
\[)?(?i:[a-z@#_][a-z0-9@$#_]{0,127})(?i:(?\[)?(?i:[a-z@#_][a-z0-9@$#_]{0,127})?(?(schemabracket)\]|)\.(? \[)?(?i:(?!net)(?!com)(?!org)([a-z@#_][a-z0-9@$#_]{0,127}))(?(objectbracket)\]|) In the "Content Search" text box on the SQL Editor toolbar, he typed "regex=..." where "..." corresponded to his regular expression. On hitting Enter, SQL-Hero got to work, scanning stored procedures, triggers and UDF's for a good "estimation" of 3-part names, based on the regular expression. When it finished, only those objects that had matches were left showing in the object tree, and Paul could easily go into each and make the necessary changes. This wouldn't have been nearly as easy if he'd only had SQL Management Studio available: a simple query against syscomments using LIKE, for example, wouldn't have cut it.
- Receive notifications about schema changes within minutes of them being applied
-
Bob was responsible for the data modeling on a system development project. After getting most of the basic tables in place, things entered more of a fine tuning stage where he would need to add columns or make minor changes. Working with the business analysts, often holed up in a meeting room, Bob could make these changes in the development database using DDL commands such as:
ALTER TABLE BusinessUnit ADD RequiresCustomer bit NOT NULL DEFAULT (0) --PUBLISH_COMMENT:Please use this field to drive customer validation instead of hard-coding to business unit GO
With a SQL-Hero notification set up to run frequently and deliver object changes, team members may receive e-mails such as:
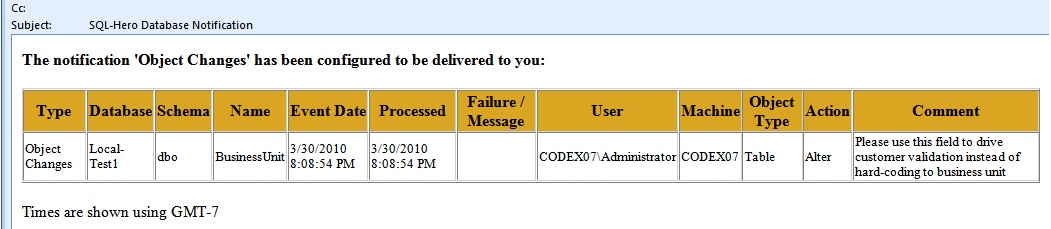
Notice how the comment Bob included when he made the schema change appears for everyone on the team. Even if Bob remembered to write an e-mail of his own to discuss the changes later, this automated notification e-mail would show up instantly at the time the change was made, keeping his team in the loop. (Considering they may be developing against these changes, this is valuable information!) Should Bob wait to apply changes until his entire team has agreed upon them? Perhaps. Different teams dictate different rules, but Bob and his team have worked effectively in this particular manner. A nice aspect of SQL-Hero is it's open enough to adapt to how you work.
- Receive summary reports from stored trace data, showing trends over time
-
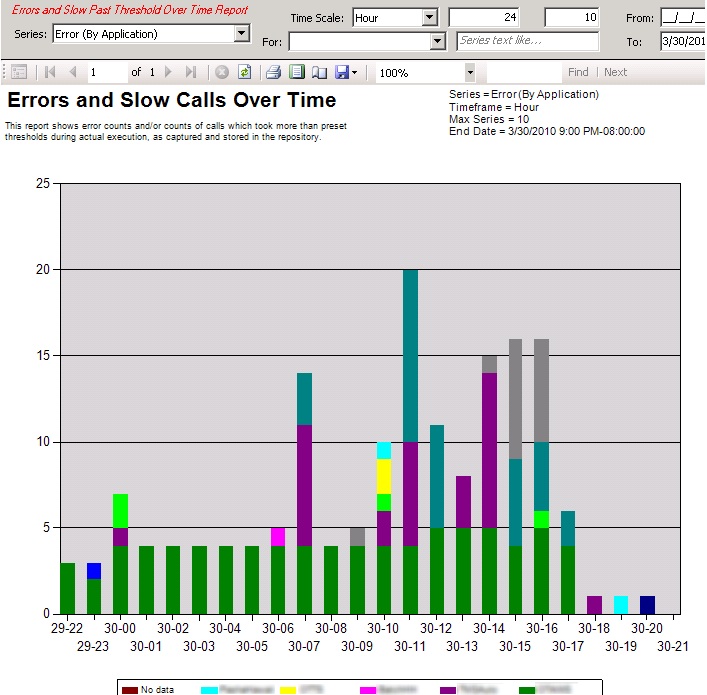
Rather than collect trace information that you have to purge frequently due to size, the SQL-Hero repository has been proven to hold a tremendous amount of trace data that can be analyzed over time. In one case Bob had a customer use daily reports to help analyze some problems processes. In fact, it became apparent that the time of day was playing a role, and using the "Managed Stored Trace" screen, he could drill into specific commands and blocking reports based on date/time filters, and even issue full-text searches against the captured commands. With some focused corrective efforts, he could prove the trend in timeouts was dropping and could convey this definitively with the customer's management team using graphical reports. The managers were pleased to have the tools available to summarize in many different ways, including by application name:
- Generate many different kinds of code, always kept in sync with your underlying structures and data
-
As data architect on a .NET development project, Bob found a sweet spot in assisting the development team be productive. He could work with business analysts to translate business needs into data structures. Some especially static data that could be hardcoded against could be turned into enumerations. Developers could write search stored procedures and other SQL retrieval logic that could be turned into strongly typed wrappers, and could populate multiple related .NET entities in a highly efficient manner. As inevitably happens, Bob would be forced to add and change schema over time. Was this a big deal for the development team and the application? Not generally. Bob would apply his change, regenerate wrapper code, .NET entities, enumerations, and so on. Based on what the framework and templates are providing, virtually everything is strongly typed in a way that immediately reveals breakages in code due to the schema changes. Developers can quickly solve the problems now revealed at compile-time, and the application is back up and running within minutes.
On top of the generated code, Bob also uses SQL-Hero to exercise unit tests against all objects in the development database changed within a certain timeframe. If there's a problem introduced by a schema change before a code generation is run, an e-mail can be sent to the last modifier of any broken stored procedure within a matter of minutes. When all these features come together, Bob's team is wowing management with high quality code, delivered quickly.
Furthermore, the team realized that users performing testing during on-going development could not very well use the development database. At the same time, a database build in this case could mean pushing all current schema and some types of data to a testing database that the users "own," in terms of the data it contains (i.e. the basis of their test cases). Bob uses SQL-Hero's SHCommand command-line tool to allow the overall build process to be automated, including the database.