URL Expression Specification
There are two main formats for source data references:
- A valid URL.
- A data reference expression.
Regular URL references include those starting with "HTTP://", "HTTPS://" or "FILE://". ("File" can reference a file that's local or accessible on a network share - not applicable for hosted xSkrape.) Data reference expressions are actually in JSON format, conforming to certain rules. The actual JSON must comply with the following object model, expressed using C#:
public class JsonEvent
{
// For: Common elements
// The canonical URL or a URL that contains a substitution parameters (eg. {0})
public string url;
// A valid processing method (default: none), one of none, step_sequential, enumerate_files, parse_json, parse_xml, step_sequential_parse_json, step_sequential_parse_xml
public string method;
// In an iterated situation, the maximum number of iterations allowed (default: 10000)
public int? max_pass;
// In an iterated situation, if the maximum number of iterations is reached, indicates whether the condition is an error or not (default: false / error)
public bool? max_pass_ok;
// Zero, one or many custom headers to include in the request
public string[] headers;
// Zero, one or many post variables to include in the request (of the form ["key", "value"])
public string[][] post;
// Default is GET, but can change via this
public string action;
// An optional username to include in the request
public string username;
// An optional password to include in the request
public string password;
// For: parse methods
// xpath expression to identify row root node(s)
public string rows_path;
// none, all, innertext - if not none, shreds text into individual xml nodes based on line breaks
public string split_lines;
// If provided, applies a text filter prior to attempting to parse for tabular data
public string prefilter;
// One or more column definitions, within each row found
public JsonEventJsonColumn[] columns;
// Optionally identify a node-set relative to the row node that provides column names as inner text of each node in the set
public string columns_path;
// Optionally identify a node-set relative to the document that provides column names
public string column_names_path;
// Optionally identify zero, one or many join_set(s)
public JoinSet[] join_sets;
public JoinSet join_set;
// For: step_sequential methods
// Defines in iterative scenarios that involve checking for stop conditions, what stop condition(s) are checked. Valid values: any, no_data, dup_data. (Default: any)
public string stop_on;
// Zero, one or many arguments that replace substitution tags in the URL during iteration
public JsonEventStepSeqArgument[] arguments;
// For: enumerate_files (not valid in hosted functions)
// Valid values: one_drive, local (default: local)
public string folder_type;
// Path specification for one or more source files
public string file_path;
// Optional filename regular expression pattern
public string filename_regex_pattern;
// Zero, one or many column specifications that are appended to the result set, pulling values from each filename involved
public JsonEventFilenameColumn[] filename_columns;
}
public class JsonEventStepSeqArgument
{
// The start value for the parameter (optional, default: 1)
public int? start;
// The step value for the parameter - the amount added to the start and then each subsequent parameter value (optional, default: 1)
public int? step;
// An optional comma or pipe delimited list of values to iterate and replace in the URL, versus using a number
public string parm_list;
// When present, the current value from the parm_list is appended to the result set in a column with this name
public string parm_column_name;
}
public class JsonEventFilenameColumn
{
// A regular expression that is applied to the source filename - the matched portion is added to the result set in the named column
public string filename_regex;
// The name of the column to append to the result set for the matched portion of the filename
public string column_name;
}
public class JsonEventJsonColumn
{
// Relative xpath spec, identifying the column value node
public string path;
// The column name to use in the result set
public string name;
// The data type to use in the result set; can include: String, DateTime, Int16, Int32, Int64, etc. (default: String)
public string datatype;
public string format;
// Can be blank or "url"; if "url", performs url encoding on the value for the column when added to the result set
public string encode;
// An additional parsing pass is possible over the candidate data to return for this column
public string parse;
// Describe the absolute text position for the start of the column data
public int? position;
// Describe the absolute text length for the column data
public int? length;
}
public class JoinSet
{
// Relative xpath spec, identifying the root of the join set
public string path;
// One or more column specifications, relative to the join set path, that belong to this join set
public JsonEventJsonColumn[] columns;
}
The following are to be taken as examples of usage of the formal object model, defined above.
| Multiple requests, sequential loop |
{ url:"urlspec" , method:"step_sequential" , headers:["CustomHeader: HeaderValue", ...] , max_pass:"looplimit" , max_pass_ok:"true|false" , stop_on:"any|no_data|dup_data" , arguments:[{start:"argstartvalue" , step:"argincrementvalue"} , parm_list:"parm_list_text" , parm_column_name:"parm_column_name"}, ...] } |
|
This allows you to issue multiple parameterized requests with the resulting data being merged into a single result set based on your table matching criteria. "arguments" can map to one or more substitution parameters in the URL, matched in order (i.e. first argument matches {0}, second matches {1}, etc.). The typical use case for this is a paged grid scenario where a query parameter such as "page" (for page number - i.e. "http://somehost/somepagename?page={0}") identifies the current page of data being rendered. urlspec - a URL used for requests that can include substitution values {0}, {1}, {2}, etc. for one or more parameters that are replaced for each request CustomHeader: HeaderValue - zero, one or more request headers can be specified in standard header format step_sequential - identifies the rule that handles multiple requests: in this case, a starting value is used with sequential incrementing until a stop condition is met looplimit - Optional; the maximum number of iterations allowed (default is 500); can act as a fail-safe max_pass_ok - Optional; the default behavior assumes "false" implying that if the looplimit is reached, it's considered an error condition; "true" implies the data is simply truncated silently at the looplimit. no_data - stops when no data is found matching the table matching criteria; dup_data - stops when data is found that matches any previously-retrieved data; any - stops when either no_data or dup_data would be satisfied argstartvalue - a numeric value representing the value used by the first request for the corresponding subsitution parameter argincrementvalue - a numeric value representing the value added to the previous request's corresponding subsitution parameter, for the next request parm_list_text - an optional string containing either pipe (|) or comma separated values that are passed to the URL (in URL encoded format) as substitution values, over multiple requests parm_column_name - when using parm_list_text, names a column in the resulting table that holds the value of the item passed to the request URL |
|
|
Parse JSON or XML as tabular data
Available version 3.0+ (non-Web), 1.0 (Web) |
{ url:"urlspec" , method:"parse_json | parse_xml" , headers:["CustomHeader: HeaderValue", ...] , rows_path:"row_xpath" , columns:[{path:"column_xpath", name:"column_name", datatype:"type_name"}, ...] , columns_path:"columns_xpath" , column_names_path:"column_names_xpath" , join_set: { path:"setroot_xpath" , columns:[{path:"column_xpath", name:"column_name", datatype:"type_name", encode:"col_encode"}, ...] } , join_sets: [ {path:"setroot_xpath" , columns:[{path:"column_xpath", name:"column_name", datatype:"type_name", encode:"col_encode"}, ...] }, ... ] } |
|
This allows you to take source data that can be interpreted as JSON or XML and shape it into a tabular format. urlspec - a URL used for the request parse_json OR parse_xml - identifies the rule that parses source data from JSON or XML into a tabular format CustomHeader: HeaderValue - zero, one or more request headers can be specified in standard header format row_xpath - an XPath expression that identifies the level at which tabular rows will be isolated (see examples) column_xpath - an XPath expression that originates under each node found from the row_path expression to retrieve data for the given column column_name - explicitly names the given column (optional - if omitted, bases on the column_path) type_name - explicitly defines the data type associated with the given column; valid values are based on .NET data types including ("String", "Int32", "DateTime", etc.). (Optional - if omitted, assumes "String") col_encode - can be "url" or omitted entirely; if "url", the values assigned in the column will be URL encoded per standard encoding rules columns_xpath - an XPath expression that originates under each node found from the row_path expression, returning a node set that represents individual columns column_names_xpath - an XPath expression that originates from the root of the document, returning a node set for which the text of each node should become the names for each column available setroot_xpath - an XPath expression that originates under each node found from the row_path expression, returning a node set that serves as the row_xpath for a nested table that is cross joined to the outer row |
|
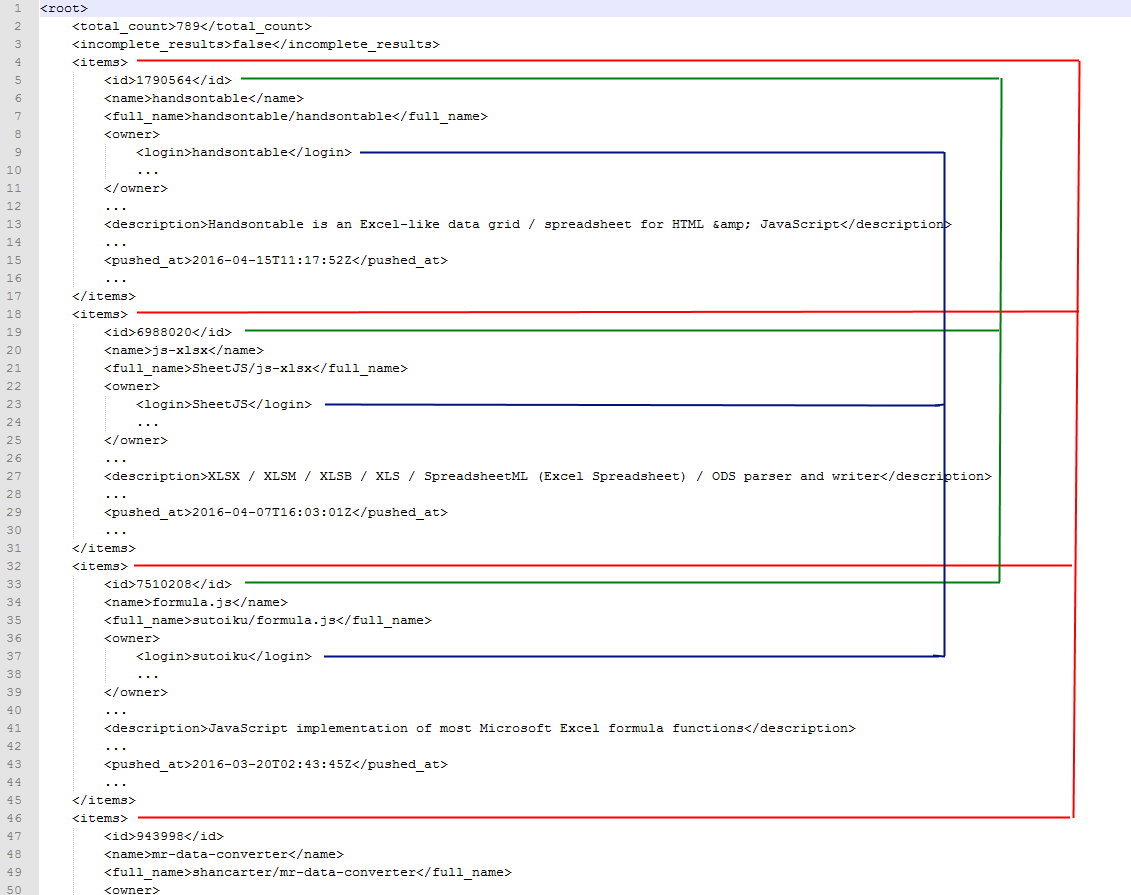
|
Multiple requests, sequential loop - JSON/XML source
Available version 3.0+ (non-Web), 1.0 (Web) |
{ url:"urlspec" , method:"step_sequential_parse_json | step_sequential_parse_xml" , headers:["CustomHeader: HeaderValue", ...] , rows_path:"row_xpath" , columns:[{path:"column_xpath", name:"column_name", datatype:"type_name"}, ...] , columns_path:"columns_xpath" , column_names_path:"column_names_xpath" , join_set: { path:"setroot_xpath" , columns:[{path:"column_xpath", name:"column_name", datatype:"type_name", encode:"col_encode"}, ...] } , join_sets: [ {path:"setroot_xpath" , columns:[{path:"column_xpath", name:"column_name", datatype:"type_name", encode:"col_encode"}, ...] }, ...] , max_pass:"looplimit" , max_pass_ok:"true|false" , stop_on:"any|no_data|dup_data" , arguments:[{start:"argstartvalue" , step:"argincrementvalue"} , parm_list:"parm_list_text" , parm_column_name:"parm_column_name"}, ...] } |
|
This is a variation of "Multiple requests, sequential loop" combined with "parse_json" / "parse_xml", described above. It allows you to merge multiple requests with the ability to parse the data from each request from JSON or XML into a tabular format. urlspec - a URL used for requests that can include substitution values {0}, {1}, {2}, etc. for one or more parameters that are replaced for each request step_sequential_parse_json OR step_sequential_parse_xml - identifies the rule that handles multiple requests AND parses source data from JSON or XML into a tabular format CustomHeader: HeaderValue - zero, one or more request headers can be specified in standard header format row_xpath - an XPath expression that identifies the level at which tabular rows will be isolated (see examples) column_xpath - an XPath expression that originates under each node found from the row_path expression to retrieve data for the given column column_name - explicitly names the given column (optional - if omitted, bases on the column_path) type_name - explicitly defines the data type associated with the given column; valid values are based on .NET data types including ("String", "Int32", "DateTime", etc.). (Optional - if omitted, assumes "String") col_encode - can be "url" or omitted entirely; if "url", the values assigned in the column will be URL encoded per standard encoding rules columns_xpath - an XPath expression that originates under each node found from the row_path expression, returning a node set that represents individual columns column_names_xpath - an XPath expression that originates from the root of the document, returning a node set for which the text of each node should become the names for each column available setroot_xpath - an XPath expression that originates under each node found from the row_path expression, returning a node set that serves as the row_xpath for a nested table that is cross joined to the outer row looplimit - Optional; the maximum number of iterations allowed (default is 500); can act as a fail-safe max_pass_ok - Optional; the default behavior assumes "false" implying that if the looplimit is reached, it's considered an error condition; "true" implies the data is simply truncated silently at the looplimit. no_data - stops when no data is found matching the table matching criteria; dup_data - stops when data is found that matches any previously-retrieved data; any - stops when either no_data or dup_data would be satisfied argstartvalue - a numeric value representing the value used by the first request for the corresponding subsitution parameter argincrementvalue - a numeric value representing the value added to the previous request's corresponding subsitution parameter, for the next request parm_list_text - an optional string containing either pipe (|) or comma separated values that are passed to the URL (in URL encoded format) as substitution values, over multiple requests parm_column_name - when using parm_list_text, names a column in the resulting table that holds the value of the item passed to the request URL |
|
|
Pass Custom Headers Only
Available version 3.0+ (non-Web), 1.0 (Web) |
{ url:"urlspec" , method:"none" , headers:["CustomHeader: HeaderValue", ...] } |
|
This allows you to issue a request using custom header values. urlspec - the URL to use for the request CustomHeader: HeaderValue - one or more request headers can be specified in standard header format |
|
Do you have a suggestion for a use case we don't support currently? Let us know!